- Главная
- Новости покера
- GTO Wizard AI разгромил LLM в покерных хедз-апах
GTO Wizard AI разгромил LLM в покерных хедз-апах
GTO Wizard провел показательный эксперимент в сфере покерных возможностей современного AI. Их агент сыграл серию хедз-апов против всех крупных языковых моделей от GPT-5.4 до Kimi K2.5 и результат получился однозначным: все модели проиграли с разгромным счетом.
5,000 раздач без шансов для LLM
ИИ всё глубже проникает в повседневную жизнь — от поиска и кода до сложной аналитики. Логично, что следующим шагом стала проверка его возможностей в играх с неполной информацией, где решают стратегия, математика и адаптация.
Результаты первой подобной проверки стали известны в конце 2025 года. Тогда стало понятно, что универсальные модели способны играть, но до стабильного высокого уровня им далеко. И вот недавно прошел новый эксперимент, в котором LLM уже играли не между собой.
GTO Wizard* опубликовал результаты масштабного бенчмарка: их специализированный AI сыграл против всех основных языковых моделей. Итог оказался однозначным — GTO Wizard AI уверенно обыграл всех конкурентов.
*GTO Wizard — команда разработчиков, создавшая платформу для обучения покеру на основе GTO-подхода и облачный солвер.
Как проходил бенчмарк GTO Wizard
В эксперименте участвовали все основные крупные модели: разные версии GPT, Claude, Gemini, Grok и Kimi.
Важно, что условия были одинаковыми для всех участников:
- ♥️ Игра в безлимитный Техасский Холдем.
- 💰 Глубокие стеки по 200bb.
- ⚔️ 5,000 раздач в хедз-ап формате.
- 🤖 Единая методология оценки через AIVAT — систему, которая снижает влияние дисперсии примерно в десять раз и позволяет оценивать не результат за столом напрямую, а качество решений с точки зрения GTO.
Важный момент: разработчики не уточнили, учитывался ли при подсчете результатов рейк. Хотя даже если пересчитать с условным рейком в 5%, это не меняет итог матча.
Результаты: полный разрыв
Итог оказался однозначным: все модели ушли в большой минус.
- Лучший результат показал GPT-5.3 XHigh Reasoning — минус 16 bb/100. Для контекста, сильные профессионалы в хедз-апе против других игроков держат уровень примерно +4 bb/100 (на этот ориентир опирается GTO Wizard).
- Худшие показатели у GPT-5.4 Nano (No Reasoning) — минус 189.7 bb/100.
| Место | Модель | Разработчик | Винрейт с поправкой на удачу (bb/100) | Ст. отклонение |
|---|---|---|---|---|
| 1 | GPT-5.3 (XHigh Reasoning) | OpenAI | -16.0 | ±3.0 |
| 2 | Marvel | MIT | -14.0 | ±4.7 |
| 3 | GPT-5.4 (XHigh Reasoning) | OpenAI | -17.8 | ±3.7 |
| 4 | GPT-5.3 (High Reasoning) | OpenAI | -18.2 | ±3.9 |
| 5 | Claude Opus 4.6 | Anthropic | -20.4 | ±4.4 |
| 6 | Gemini 3.1 Pro | ~-30.8 | — | |
| 7 | Kimi K2.5 | Moonshot AI | ~-40 до -50 | — |
| 8 | Grok 4 | xAI | ~-60 | — |
| 9 | GPT-4o / более старые базовые модели | OpenAI | < -100 | — |
| 10 | GPT-5.4 Nano (No Reasoning) | OpenAI | -189.7 | — |
Почему LLM проиграли
После анализа раздач команда GTO Wizard выделила четыре системные причины, которые мешают универсальным моделям играть в покер на высоком уровне:
- 🕶️ Скрытая информация. Модель не видит карты оппонента и вынуждена работать только с вероятностями.
- ⚖️ Балансировка диапазонов. В покере тысячи ситуаций, где любое смещение стратегии делает игрока уязвимым.
- 🧠 Долгосрочное планирование. Каждое решение влияет на последующие улицы, и ошибки накапливают EV-потери.
- ❓ Моделирование поведения оппонента в условиях неопределенности. Это требует устойчивой вероятностной модели, которой у LLM нет в явном виде.
Дополнительно выявлена базовая проблема: даже продвинутые модели примерно в 2% случаев неверно интерпретируют собственные карты, путая масти и комбинации. В покере такие ошибки мгновенно превращаются в минус EV.
В чем сила GTO Wizard AI
Разработчики отмечают, что GTO Wizard AI действует вблизи равновесных стратегий Нэша, что делает его крайне трудно эксплойтируемым.
Ориентир, который они используют, — около 4 bb/100 как уровень элитных игроков против поля. Однако против специализированного AI даже такие игроки, по логике модели, будут уходить в минус.
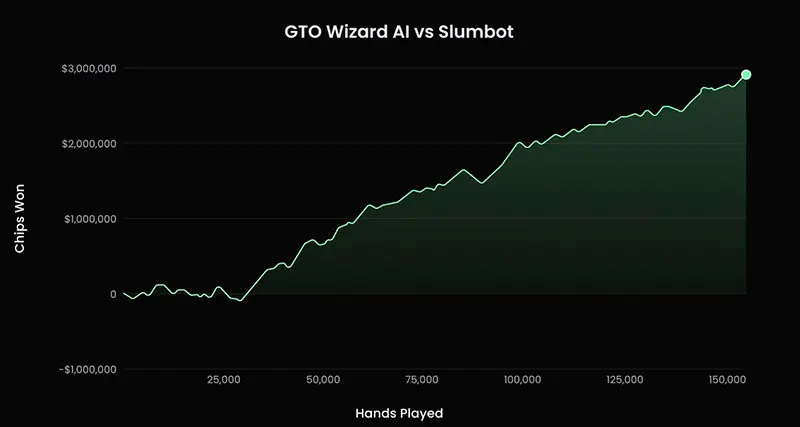
Техническая основа системы — Ruse AI, разработанный канадскими исследователями Филиппом Бердселлом и Марком-Антуаном Провостом. В 2023 году он обыграл Slumbot, одного из сильнейших публичных покерных ботов, с результатом +19.4 bb/100 на дистанции 150,000 рук. Позже проект был интегрирован в экосистему GTO Wizard и стал базой текущего AI-движка.
Отдельно стоит сам формат эксперимента. GTO Wizard сделал бенчмарк публичным: любой разработчик может подключить своего агента через API и сыграть те же HU-матчи. Это фактически превращает систему в единый стандарт оценки покерного AI и позволяет напрямую сравнивать разные модели в одинаковых условиях.
GTO Wizard vs LLM: главный вывод
Результаты эксперимента однозначны. Универсальные языковые модели пока не способны конкурировать со специализированными покерными агентами даже в формате игры один на один.
Разрыв между подходами оказался системным, а не случайным. Он хорошо показывает текущую границу возможностей: универсальный интеллект против узкоспециализированной оптимизации.
Покер в этой истории выступает не как игра, а как строгий тест на пределы возможностей современных LLM.
World Series of Poker 2026 стартовала в Лас-Вегасе 26 мая. Здесь мы собрали результаты в�сех турни...
WPT Global сделал серьезный шаг в развитии своего приложения, интегрировав в него AI-тренера Quin...
В России живой покер находится в особом статусе. Играть на деньги легально только в специальных и...
В этой статье мы рассказываем о нашем опыте участия в конференции iGB Live, которая каждое лето п...